О реализации словарей в Python
В этом посте описывается, как словари реализованы в языке Python.
Эта статья на самом деле является репостом того, что было первоначально опубликовано в блоге Лорана Люса 29 августа 2011 года Лораном Люсом. Я являюсь наставником нескольких студентов курсов русского языка Learn Python. У них есть вопросы о структурах Python и о том, как их использовать. Я нашел этот пост хорошим подспорьем для себя и, возможно, для моих учеников.
Словари индексируются по ключам и их можно рассматривать как ассоциативные массивы. Давайте добавим в словарь 3 пары ключ/значение:
>>> d = {'a': 1, 'b': 2}
>>> d['c'] = 3
>>> d
{'a': 1, 'b': 2, 'c': 3}
Доступ к значениям можно получить следующим образом:
>>> d['a']
1
>>> d['b']
2
>>> d['c']
3
>>> d['d']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'd'
Ключ «d» не существует, поэтому возникает исключение KeyError.
Хэш-таблицы
Словари Python реализованы с использованием хэш-таблиц. Это массив, индексы которого получаются с помощью хэш-функции ключей. Цель хеш-функции — равномерно распределить ключи в массиве. Хорошая хэш-функция минимизирует количество коллизий, например. разные ключи имеют один и тот же хеш. В Python нет такой хэш-функции. Его наиболее важные хэш-функции (для строк и целых чисел) в общих случаях очень регулярны:
>>> map(hash, (0, 1, 2, 3))
[0, 1, 2, 3]
>>> map(hash, ("namea", "nameb", "namec", "named"))
[-1658398457, -1658398460, -1658398459, -1658398462]
В оставшейся части статьи мы будем предполагать, что используем строки в качестве ключей. Хэш-функция для строк в Python определяется как:
arguments: string object
returns: hash
function string_hash:
if hash cached:
return it
set len to string's length
initialize var p pointing to 1st char of string object
set x to value pointed by p left shifted by 7 bits
while len >= 0:
set var x to (1000003 * x) xor value pointed by p
increment pointer p
set x to x xor length of string object
cache x as the hash so we don't need to calculate it again
return x as the hash
Если вы запустите hash(‘a’) в Python, он выполнит string_hash() и вернет 12416037344. Здесь мы предполагаем, что используем 64-битную машину.
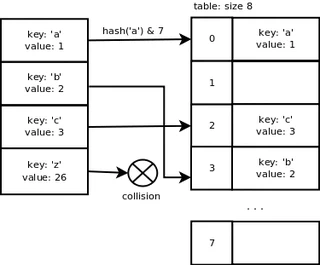
Если для хранения пар ключ/значение используется массив размера x, то мы используем маску, равную x-1, для вычисления индекса слота пары в массиве. Это ускоряет вычисление индекса слота. Вероятность найти пустой слот высока благодаря механизму изменения размера, описанному ниже. Это означает, что в большинстве случаев имеет смысл провести простое вычисление. Если размер массива равен 8, индекс для «a» будет следующим: хеш («a») & 7 = 0. Индекс для «b» равен 3, индекс для «c» равен 2, индекс для «z» равен 3, что совпадает с индексом «b», здесь мы имеем коллизию.
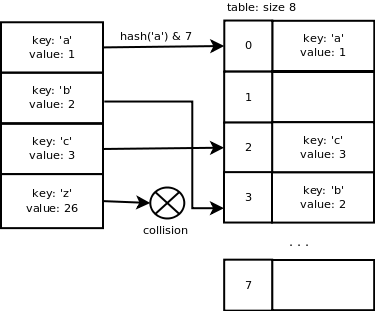
Мы видим, что хеш-функция Python хорошо справляется со своей задачей, когда ключи идут последовательно, и это хорошо, поскольку довольно часто приходится работать с данными такого типа. Однако как только мы добавим ключ «z», произойдет коллизия, поскольку он недостаточно последователен.
Мы могли бы использовать связанный список для хранения пар, имеющих одинаковый хэш, но это увеличило бы время поиска, например. больше не среднее значение O (1). В следующем разделе описывается метод разрешения коллизий, используемый в словарях Python.
Открытая адресация
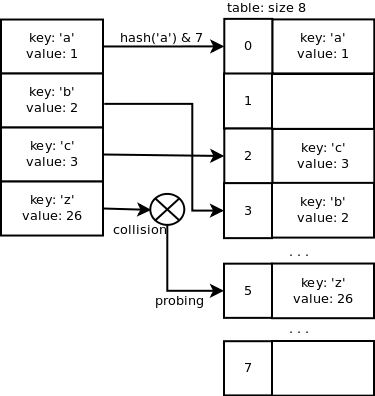
Открытая адресация — это метод разрешения коллизий, в котором используется зондирование. В случае «z» индекс слота 3 уже используется в массиве, поэтому нам нужно поискать другой индекс, чтобы найти тот, который еще не используется. Добавление пары ключ/значение усреднит O(1), а также операцию поиска.
Для поиска свободного слота используется квадратичная последовательность зондирования. Код следующий:
j = (5*j) + 1 + perturb;
perturb >>= PERTURB_SHIFT;
use j % 2**i as the next table index;
Повторение 5*j+1 быстро увеличивает небольшие различия в битах, которые не повлияли на исходный индекс. Переменная «perturb» активирует остальные биты хеш-кода.
Просто из любопытства давайте посмотрим на последовательность проверки, когда размер таблицы равен 32 и j = 3.
3 -> 11 -> 19 -> 29 -> 5 -> 6 -> 16 -> 31 -> 28 -> 13 -> 2…
Вы можете узнать больше об этой последовательности проверки, посмотрев исходный код dictobject.c. Подробное объяснение механизма зондирования можно найти в верхней части файла.
Теперь давайте рассмотрим внутренний код Python и пример.
Структуры словаря C
Для хранения словарной статьи используется следующая структура C: пара ключ/значение. Хэш, ключ и значение сохраняются. PyObject — это базовый класс объектов Python.
typedef struct {
Py_ssize_t me_hash;
PyObject *me_key;
PyObject *me_value;
} PyDictEntry;
Следующая структура представляет словарь. ma_fill — количество используемых слотов + пустые слоты. Слот помечается как фиктивный при удалении пары ключей. ma_used — количество используемых слотов (активных). ma_mask равен размеру массива минус 1 и используется для расчета индекса слота. ma_table — это массив, а ma_smalltable — исходный массив размером 8.
typedef struct _dictobject PyDictObject;
struct _dictobject {
PyObject_HEAD
Py_ssize_t ma_fill;
Py_ssize_t ma_used;
Py_ssize_t ma_mask;
PyDictEntry *ma_table;
PyDictEntry *(*ma_lookup)(PyDictObject *mp, PyObject *key, long hash);
PyDictEntry ma_smalltable[PyDict_MINSIZE];
};
Инициализация словаря
Когда вы впервые создаете словарь, вызывается функция PyDict_New(). Я удалил некоторые строки и преобразовал код C в псевдокод, чтобы сосредоточиться на ключевых понятиях.
returns new dictionary object
function PyDict_New:
allocate new dictionary object
clear dictionary's table
set dictionary's number of used slots + dummy slots (ma_fill) to 0
set dictionary's number of active slots (ma_used) to 0
set dictionary's mask (ma_value) to dictionary size - 1 = 7
set dictionary's lookup function to lookdict_string
return allocated dictionary object
Добавление элементов
Когда добавляется новая пара ключ/значение, вызывается PyDict_SetItem(). Эта функция принимает указатель на объект словаря и пару ключ/значение. Он проверяет, является ли ключ строкой, и вычисляет хэш или повторно использует кэшированный ключ, если он существует. Insertdict() вызывается для добавления новой пары ключ/значение, и размер словаря изменяется, если количество используемых слотов + фиктивных слотов превышает 2/3 размера массива. Почему 2/3? Это делается для того, чтобы зондирующая последовательность могла найти свободный слот достаточно быстро. Функцию изменения размера мы рассмотрим позже.
arguments: dictionary, key, value
returns: 0 if OK or -1
function PyDict_SetItem:
if key's hash cached:
use hash
else:
calculate hash
call insertdict with dictionary object, key, hash and value
if key/value pair added successfully and capacity over 2/3:
call dictresize to resize dictionary's table
inserdict() использует функцию поиска lookdict_string() для поиска свободного слота. Это та же функция, которая используется для поиска ключа. lookdict_string() вычисляет индекс слота, используя значения хеша и маски. Если он не может найти ключ в индексе слота = хеше и маске, он начинает проверку с использованием описанного выше цикла, пока не найдет свободный слот. При первой попытке зондирования, если ключ равен нулю, он возвращает фиктивный слот, если он найден во время первого поиска. Это дает приоритет повторному использованию ранее удаленных слотов.
Мы хотим добавить следующие пары ключ/значение: {‘a’: 1, ‘b’: 2’, ‘z’: 26, ‘y’: 25, ‘c’: 5, ‘x’: 24}. Вот что происходит:
Структура словаря выделяется с размером внутренней таблицы 8.
- PyDict_SetItem: key = 'a', value = 1
- hash = hash('a') = 12416037344
- insertdict
- lookdict_string
- индекс слота = хэш и маска = 12416037344 и 7 = 0
- слот 0 не используется, поэтому верните его
- инициализировать запись с индексом 0 с ключом, значением и хешем
- ma_used = 1, ma_fill = 1
- PyDict_SetItem: key = 'b', value = 2
- hash = hash('b') = 12544037731
- insertdict
- lookdict_string
- индекс слота = хеш и маска = 12544037731 и 7 = 3
- слот 3 не используется, поэтому верните его
- инициализация записи по индексу 3 с ключом, значением и хешем
- ma_used = 2, ma_fill = 2
- PyDict_SetItem: key = 'z', value = 26
- hash = hash('z') = 15616046971
- insertdict
- lookdict_string
- индекс слота = хэш и маска = 15616046971 и 7 = 3
- используется слот 3, поэтому проверьте другой слот: 5 свободен
- инициализировать запись с индексом 5 с ключом, значением и хешем
- ma_used = 3, ma_fill = 3
- PyDict_SetItem: key = 'y', value = 25
- hash = hash('y') = 15488046584
- insertdict
- lookdict_string
- индекс слота = хеш и маска = 15488046584 и 7 = 0
- используется слот 0, поэтому проверьте другой слот: 1 свободен
- инициализировать запись с индексом 1 с ключом, значением и хешем
- ma_used = 4, ma_fill = 4
- PyDict_SetItem: key = 'c', value = 3
- hash = hash('c') = 12672038114
- insertdict
- lookdict_string
- индекс слота = хэш и маска = 12672038114 и 7 = 2
- слот 2 свободен, поэтому верните его
- инициализация записи по индексу 2 с ключом, значением и хешем
- ma_used = 5, ma_fill = 5
- PyDict_SetItem: key = 'x', value = 24
- hash = hash('x') = 15360046201
- insertdict
- lookdict_string
- индекс слота = хэш и маска = 15360046201 и 7 = 1
- используется слот 1, поэтому проверьте другой слот: 7 свободен
- инициализировать запись с индексом 7 с ключом, значением и хешем
- ma_used = 6, ma_fill = 6
Вот что у нас есть на данный момент:

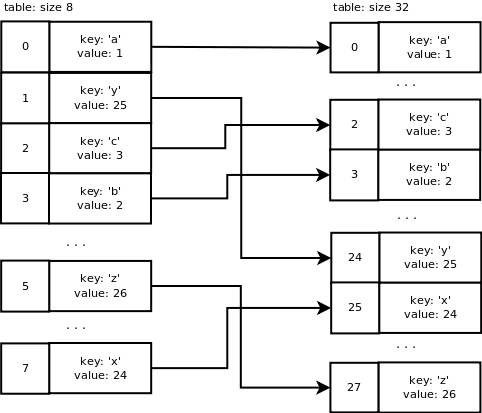
Сейчас используются 6 слотов из 8, поэтому мы используем более 2/3 емкости массива. dictresize() вызывается для выделения большего массива. Эта функция также занимается копированием старых записей таблицы в новую таблицу.
dictresize() вызывается с minused = 24, в нашем случае это 4 * ma_used. 2 * ma_used используется, когда количество используемых слотов очень велико (более 50000). Почему в 4 раза больше используемых слотов? Это уменьшает количество шагов изменения размера и увеличивает разреженность.
Новый размер таблицы должен быть больше 24, и он рассчитывается путем сдвига текущего размера на 1 бит влево до тех пор, пока он не станет больше 24. В конечном итоге он будет равен 32, например. 8 -> 16 -> 32.
Вот что происходит с нашей таблицей при изменении размера: выделяется новая таблица размером 32. Записи старой таблицы вставляются в новую таблицу с использованием нового значения маски, равного 31. В итоге мы получаем следующее:
Удаление элементов
PyDict_DelItem() вызывается для удаления записи. Для этого ключа вычисляется хэш и вызывается функция поиска для возврата записи. Слот теперь является фиктивным.
Мы хотим удалить ключ «c» из нашего словаря. В итоге мы имеем следующий массив:
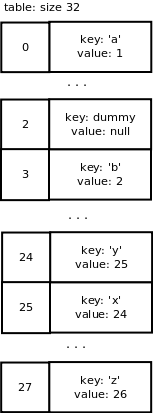
Обратите внимание, что операция удаления элемента не вызывает изменение размера массива, если количество используемых слотов намного меньше общего количества слотов. Однако при добавлении пары ключ/значение необходимость изменения размера зависит от количества используемых слотов + фиктивных слотов, поэтому массив также может быть уменьшен.
На этом пока всё. Надеюсь, вам понравилась статья. Пожалуйста, напишите комментарий, если у вас есть какие-либо отзывы.
Первоначально опубликовано в блоге Лорана Люса 29 августа 2011 г. Лораном Люсом.

Архитектор ПО, Архитектор данных
Опытный разработчик ПО с опытом работы в стартапах, банках и отраслях вроде космоса и железных дорог.
- Инженер Go, Python, C++, C с 2006 года.
- Последние 3 года: инженерия платформ, создание внутренних порталов разработчиков (IDP) и сдвиг организаций влево в DevOps.
- Проектировал и строил автономные и клиент-серверные приложения с базами Oracle DB, PostgreSQL и MySQL.
- Разрабатывал CRM-системы, веб-автоматизированную обработку заказов и симуляции для эксплуатации железнодорожного подвижного состава.